
The following is an edit of the original article on Zilliz.com. It demonstrates how to enhance an SME's knowledge and make their writing more concise and readable with technical writing principles.
Vector Databases 101 - Part 1
Intro to Unstructured Data
August 31, 2025
Data helps drive the modern, global economy. Everything from social media videos to vehicle GPS coordinates and heart rate sensors generates new data at an exponential rate every day. You cannot overstate the importance of this increasing data flow because quality data enables businesses to:
- Improve customer service
- Uncover supply chain weaknesses
- Pinpoint inefficiencies
- Identify new market opportunities
Moreover, the International Data Corporation predicts that the global datasphere—the total amount of new data created and kept in persistent storage—will grow to 400 zettabytes by 2028. By that time, Unstructured Data will occupy 80% of all the data generated.
Note: One zettabyte = 1021 bytes.
Vector Databases work with Unstructured Data. That's why Part 1 of this series starts by explaining this data type. First, you'll learn how to differentiate between Unstructured Data and traditional Structured/Semi-Structured Data. Lastly you'll examine Embeddings.
Introducing Structured Data
MySQL and PostgreSQL are popular relational databases that store Structured Data. These databases store data in a table-based format, each with a unique set of columns. Furthermore, relational databases typify deterministic systems that return exact matches.
Examine the book database below as an example of Structured Data storage. Each row represents a particular book indexed by an ISBN number, while the columns list the corresponding category of information.
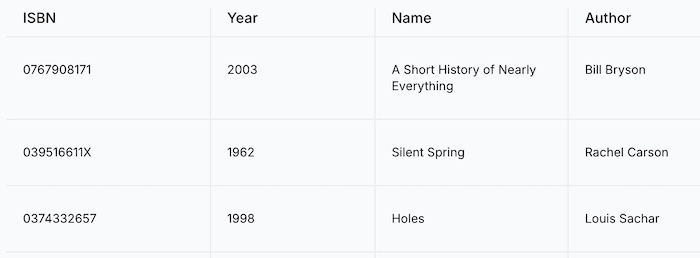
ISBN
Source: Zilliz.com
What Is Semi-Structured Data?
Semi-Structured Data—a subset of Structured Data—does not conform to the traditional, table-based model. Instead, keys describe and index the data. Therefore, you can store Semi-Structured Data in single or multi-level, array key-value stores.
Notice how you can transform the same data from the book database above into the semi-structured JSON format below:
{
ISBN: 0767908171
Month: February
Year: 2003
Name: A Short History of Nearly Everything
Author: Bill Bryson
Tags: geology, biology, physics
},
{
ISBN: 039516611X
Name: Silent Spring
Author: Rachel Carson
},
{
ISBN: 0374332657
Year: 1998
Name: Holes
Author: Louis Sachar
},
The first element in this new JSON database now contains the additional Month and Tags keys. Also, notice how these additions didn't impact the two subsequent elements. That's because with Semi-Structured Data, you can add new elements without adding extra columns. Thus, Semi-Structured data allows for greater flexibility.
NoSQL is typically the database of choice for Semi-Structured Data, as its non-tabular format prevents it from being used as a relational database. Three other popular databases for this data type are Cassandra, MongoDB, and Redis.
Understanding Unstructured Data
Unstructured Data refers to data that you cannot fit into an existing data model. Human-generated data, such as images, video, audio, and text files, exemplify Unstructured Data. However, other examples include protein structures, executable file hashes, and even human-readable code.
Examples of Unstructured Data
Machines and humans can generate Unstructured Data. Some machine-generated examples include:
- Sensor data generated by temperature sensors, humidity sensors, GPS sensors, and motion sensors.
- Machine Log data generated by machines, devices, or applications includes system logs, application logs, and event logs.
- Internet of Things data collected from smart devices, such as smart thermostats, smart home assistants, and wearable devices.
- Computer Vision data generated by computer vision technologies, such as image recognition, object detection, and video analysis.
- Natural Language Processing data includes speech recognition, language translation, and sentiment analysis.
- Web and Application data generated by web servers, web applications, and mobile applications, and includes user behavior data, error logs, and application performance data.
Examples of human-generated Unstructured Data:
- Emails: These messages contain free-form text, images, and attachments.
- Text Messages: Texts can be informal, unstructured, and contain abbreviations or emojis.
- Social Media Posts: These posts can vary in structure and content, including text, images, videos, and hashtags.
- Audio Recordings: Human-generated audio can include phone calls, voicemails, audio files, and audio notes.
- Handwritten Notes: Notes can be data that contains drawings, diagrams, and other visual elements.
- Meeting Notes: These can contain unstructured text, diagrams, and action items.
- Transcripts: Includes speeches, interviews, and meetings that can contain unstructured text.
- User-Generated Content: Website and forum content can include free-form text, images, and video files.
Unstructured Data has no fixed format. However, since it's poised to make up a whopping 80% of all newly created data by 2028, the challenge of how to transform, store, and search it emerges with a sense of urgency. Thankfully, there is a solution—Large Language Models (LLMs).
A Crash Course on Embeddings
Most LLMs can transform a single piece of Unstructured Data into a list of floating-point values known as "embeddings" or "embedding vectors." They represent the semantic content of the data. Thus, searching through Unstructured Data boils down to vector arithmetic.
Note: Handcrafted algorithms can also generate embeddings.
Below is an example of an LLM's output when it transforms a piece of Unstructured Data into a vector. More specifically, the ResNet-50 convolutional neural network represents this bird photograph as a vector of length 2048 with the first three and last three elements being: [0.1392, 0.3572, 0.1988, ..., 0.2888, 0.6611, 0.2909].

Eastern Towhee
Source: Zilliz.com
Unstructured Data Processing
Searching for Structured/Semi-Structured data in a database is pretty straightforward. For example, to query the first book from a particular author with MongoDB, you could submit the following code snippet in pymongo:
>>> document = collection.find_one({'Author': 'Bill Bryson'})
This type of querying is standard for traditional databases. However, vector database queries specify an input query vector as opposed to using a SQL statement. So, you could query the Milvus vector database with the following pymilvus snippet:
>>> results = collection.search(embedding, 'embedding', params, limit=10)
By utilizing innovative indexing methods, vector databases demonstrate a precise tradeoff between accuracy and performance. In other words, increasing search runtimes helps the database perform more closely to a traditional, deterministic system. Conversely, reducing search runtimes improves throughput. However, it might return fewer of a query's actual nearest neighbors (see below). Thus, processing Unstructured Data remains a probabilistic, rather than a deterministic process.
Approximate Nearest Neighbor
Queries across extensive collections of Unstructured Data utilize a suite of algorithms collectively known as Approximate Nearest Neighbor (ANN). ANN optimizes the search process by finding the closest point (or set of points) to a given query vector. Hence, the "approximate" in ANN.
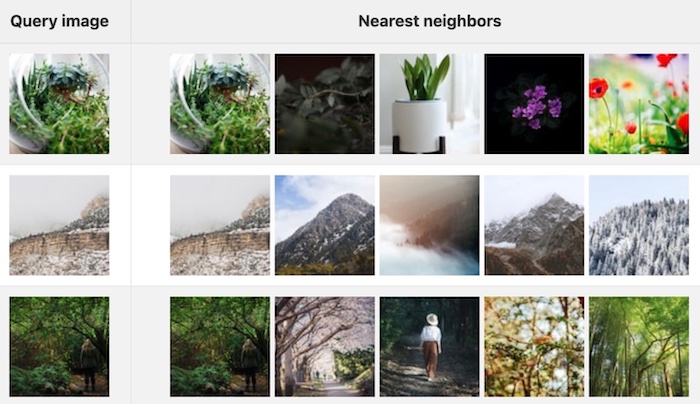
Visual Example of Approximate Nearest Neighbor Search
Source: Zilliz.com
ANN search is a core component of vector databases. However, a deeper explanation would require its own article. So, you will find more information on various ANN search methodologies later in this series of articles.
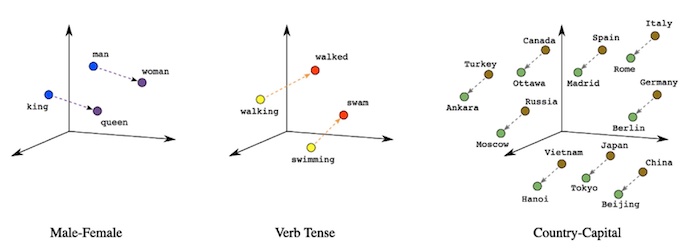
Embedding Algorithm
Source: Zilliz.com
Key Takeaways
Before moving on to Part II of this series, take a moment to review the key takeaways from this article:
- Structured/Semi-Structured Data describes numeric, string, or time data types. Structured Data is organized into tables, enabling analysts to search and analyze it with traditional tools such as SQL. Querying across Structured/Semi-Structured Data is a deterministic process resulting in exact matches.
- Unstructured Data is represented as high-dimensional vectors. These vectors (aka embeddings) excellently represent semantic content for this data type. Moreover, Unstructured Data usage will continue to rise as industries mature and implement better methods for processing it.
- ANN is a suite of algorithms that handles searching and analyzing Unstructured Data. The process is inherently probabilistic.
- Vector Databases process Unstructured Data. To understand this process requires a complete paradigm shift.
This concludes Part 1 of this series. Read Part II for an in-depth view of Vector Databases.
