
Introduction to Large Language Models - Part 1
July 4, 2025
Large Language Models (LLMs) are sophisticated AI models trained on massive datasets of text and code. Furthermore, because they excel at understanding, generating, and manipulating human language. LLMs can:
- Answer questions
- Translate languages
- Summarize text
- Generate creative content
If you're interested in learning how LLMs operate, Andrej Karpathy, former director of AI at Tesla, created an excellent video on the subject "Deep Dive into LLMs like ChatGPT." You can watch it here or read the condensed, text version below:
Sourcing High-Quality Data
To properly train an LLM, you'll need a ton of text from publicly available sources—more specifically, a large, diverse set of high-quality documents. To obtain such data, you must employ URL filtering techniques. URL filtering blocks data from the following websites:
- Malware sites
- Spam sites
- Marketing sites
- Adult sites
- Other similar sites
You must also filter websites that contain personally identifiable information (such as Social Security numbers) and exclude them from the dataset. After cleansing the data, you'll end up with the final text for the training set.
The Tokenization Process
Next, you'll train Neural Networks on this data. But first, you must convert the text to raw bits—1s and 0s. Unfortunately, combining 1s and 0s adds up to very long symbol sequences which escalates costs for Neural Networks.

One way to compress sequence length is to group eight consecutive bits into a single byte. You can tweak a group of eight bits into 256 possible combinations (each number ranges from 0 to 255). However, rather than thinking of this range as numbers, think of them as unique IDs or unique symbols.
Since the goal is to continually shrink the sequence length, you can run the "Byte Pair Encoding Algorithm." It searches for commonly recurring bytes or symbols. For example, imagine that the token sequence '116' followed by '32' (116 32) appears frequently. In this case, the algorithm could mint a symbol with an ID of 256 to represent and shorten every pair of 116 and 32.
Moreover, you can run this algorithm as many times as you want. Each time the algorithm mints a new symbol, the number of symbols increases while the sequence length decreases.
The process of converting raw text into symbols (or tokens) is called "tokenization." Tokenization converts text into tokens and then back into text. You can see how tokenization works by visiting Tiktokenizer and typing in the following:
- Select gpt-4o.
- Type "hello world."
- Examine the output.
You'll see the case-sensitive symbols: 24912, 2375. The token ID: 24912 represents the lowercase "hello." However, tokenization considers the space between the two words "hello world." Thus, "world" and " world" will have different IDs. Including the space, " world" has the ID: 2375.
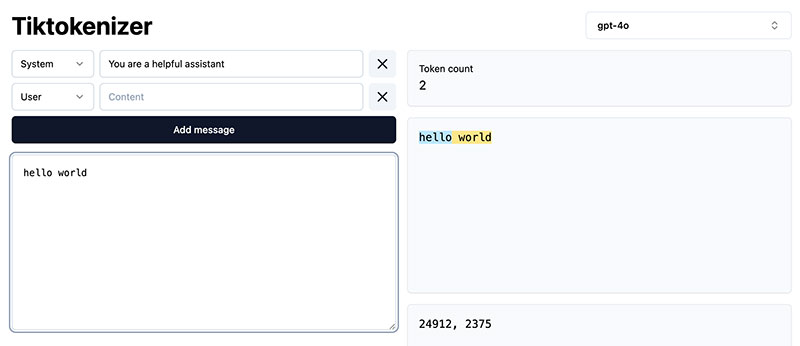
Source: Tiktokenizer
Now you've taken a sequence of text in the data set and re-represented it. With Tiktokenizer, you can type any text and see how GPT-4 views it as symbols.
Note: "GPT" stands for Generative Pre-trained Transformer.
Updating the Neural Network
Its essential to understand Neural Networks' inputs and outputs. Inputs are token sequences of variable lengths that run between zero and your predetermined maximum size. The output becomes a prediction of which token comes next in the sequence.
The Neural Network can choose from 100,277 possible symbols and it will output exactly that many numbers. Further, all of these numbers correspond to the probability of the next token appearing in the sequence. The network is simply guessing which number comes next.
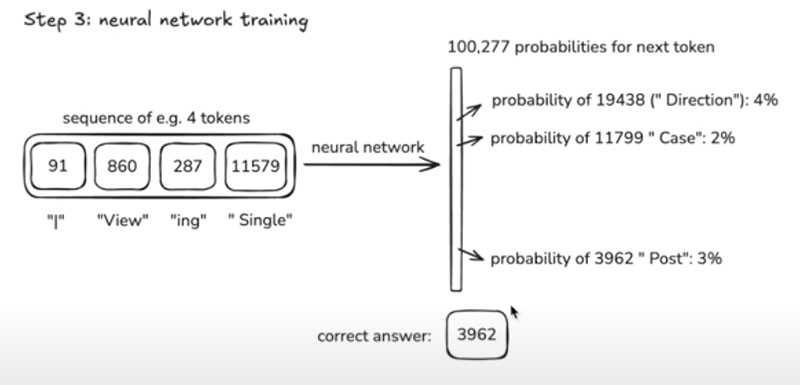
Source: Andrej Karpathy "Deep Dive into LLMs like ChatGPT."
The Neural Network states that the probability of the token 19438 (space_ " Direction") is 4%. Additionally, the likelihood of 11799 (space_ " Case") is 2%. The correct answer is 3962 (space_ " Post"), which has a 3% probability.
The Neural Network now needs fine-tuning because you want the probability of the correct answer " Post" to be higher than 3%. You also need the probabilities of the other tokens to be lower.
You must update the Neural Network so that the next time it sees this particular sequence of tokens, it will adjust the probabilities. " Post" should go up to something like 4% and " Case" should drop down to approximately 1% while " Direction" could also move lower to about 2%.

Source: Andrej Karpathy "Deep Dive into LLMs like ChatGPT"
Notice how you nudge the network to assign a higher probability to the correct token that's supposed to appear next in the sequence. Remember, this process continues beyond the current token sequence to wherever the network encounters the same token sequence throughout the entire dataset.
You sample more batches, and each time this token sequence appears, you adjust the Neural Network so that the probability of that next correct token becomes slightly higher. This process happens in parallel and in large batches of tokens.
To sum up, training the Neural Network involves a sequence of updates to make predictions statistically match the data in your training set. The goal is to make probabilities consistent with the statistical patterns of how these tokens follow each other in sequence.
Tweaking the Knobs
When training Neural Networks, you want to model the statistical relationships between tokens and how they follow each other. To start, you dig into the data and select windows of tokens and randomly initialize the network. Initially, the training probabilities will also be random.
The windows' length can range anywhere from zero tokens up to the predetermined maximum size. In principle, you can use arbitrary window lengths of tokens. However, in practice, you will typically only see window lengths up to 8,000 tokens. Capping the length prevents processing very long window sequences, which would be computationally expensive. So you pick an appropriate number and crop it to that length.
In the example of input token sequences below, you can see four inputs. These inputs will get mixed together with parameters (also referred to as weights). In the example below, you see six example parameters. But in practice, modern Neural Networks will have billions of parameters.

Source: Andrej Karpathy "Deep Dive into LLMs like ChatGPT"
To start, the Neural Network makes predictions and randomly sets these parameters. However, you adjust the parameters through a process of iteratively updating the network (training the Neural Network). Once again, the goal is to generate outputs that are consistent with the patterns in the training data.
Andrej Karpathy analogizes these parameters as "knobs on a DJ set." As you tweak the knobs you get different predictions for every possible token sequence input.

Source: Andrej Karpathy "Deep Dive into LLMs like ChatGPT"
Notice the inputs such as x1 and x2. These inputs get mixed with the parameters, w1, w2, etc. The mixing process utilizes fairly simple mathematical expressions such as multiplication, addition, exponentiation, and division.
Introducing Transformers
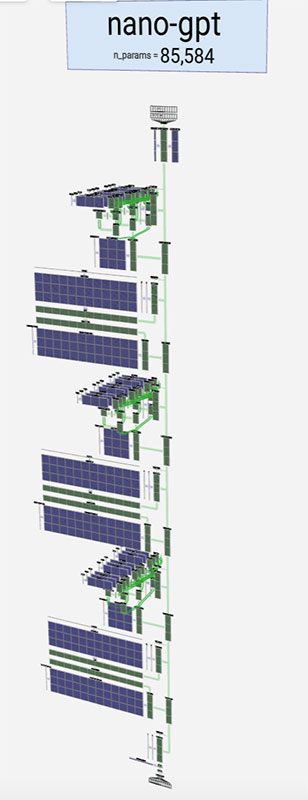
Example of a Transformer. Source: bbycroft.net
The Neural Network above is a special kind of structure called a Transformer. Transformers are a type of Neural Network architecture. You can think of them as giant mathematical expressions. This one contains roughly 85,000 parameters.
The inputs (token sequences) enter the Transformer at the top of the graphic. The middle of the graphic is where a sequence of transformations takes place. The Transformer produces intermediate values within these mathematical expressions as it attempts to predict the next token. At the bottom, you'll see the Transformer's output. This location is also where the Logit Softmax resides.
What Are Logits and Softmax?
Logits and Softmax handle classification tasks. Logits are the raw outputs of a Neural Network's final layer. They represent the model's scores or "guesses," and they can be any real number.
Softmax is an activation function applied to the Logits to convert them into a probability distribution. The network takes a vector of Logits and transforms it into a vector of probabilities that sum to 1.
We won't cover all the details in this graphic. For now, just understand that a Transformer is a mathematical function with a fixed set of parameters that transforms an input sequence into an output sequence. As you tweak the parameters you get different kinds of predictions.
Understanding Inference
"Inference" is another step in the Neural Networks' journey. In the Inference stage, the model generates new data.
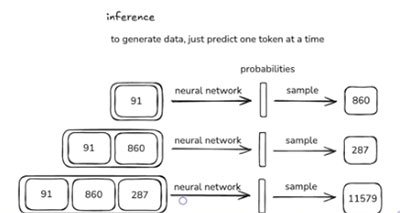
Generating from the model is relatively straightforward. You start with some tokens, like a prefix. For example, you could start with the token 91 and feed it into the network. The network would return the probability vector.
Now you can sample a token from this probability distribution to get a single, unique token. The network is more likely to sample tokens with a high probability. For example, token 860 is a better candidate because it follows 91 in the training data.
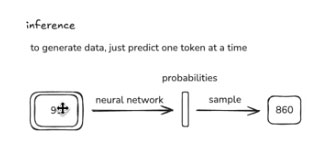
Source: Andrej Karpathy "Deep Dive into LLMs like ChatGPT"
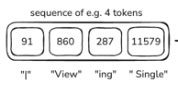
Source: Andrej Karpathy "Deep Dive into LLMs like ChatGPT"
860 comes after 91, so you would append it. Next, you sample what the third token will be. Let's say that it's 287. Now you have a sequence of three tokens. The next step is to ask what the fourth token is likely to be. You sample and get 11579.
Source: Andrej Karpathy "Deep Dive into LLMs like ChatGPT"
The token 11579 corresponds to " article" (remember the space). So the four tokens read "|" "View" "ing" "Single" "Article." Note that the first token is the bar symbol "|" (not the capital "i"). In this case, you didn't reproduce the sequence in the training data. 11579 is not the same as the 3962 you had before.
So keep in mind that these systems are stochastic. "Stochastic" describes systems in which randomness and uncertainty play a key role in their outcomes. They differ from deterministic systems, which produce the same output for a given input.
With stochastic systems, you may occasionally receive a token that was not part of the documents in the training data because the token sequence may not be identical to that training data. However, the data can still inspire the output.
So, Inference is just the process of making a prediction from these distributions one at a time. In many cases, you would download the entire internet and tokenize it as a pre-processing step. However, you only have to do that one time. Once you have a token sequence, you can start training networks.
To be practical, you need to train multiple networks of different sizes, settings, and arrangements. That requires a lot of Neural Network training. After training, you end up with a specific set of parameters. Now, you can perform Inference. In other words, the model can start generating data.
GPT-2 vs. GPT-4
When you're using ChatGPT and typing text into a model, understand that OpenAI trained that model for months prior. It runs a specific set of fixed parameters that work well. And when you ask the model questions, you're dealing with Inference. There's no more training. Now, you're talking to the model directly.
OpenAI published GPT-2 in 2019. It was a Transformer Neural Network, similar to the ones you work with today. However, it had 1.6 billion parameters, compared to modern Transformers, which have from several hundred billion to a trillion parameters.
The number of parameters continue to grow while costs continue to shrink. The reason is that datasets have improved significantly, and the methods used for filtering, extracting, and preparing them have become much more refined. The datasets exhibit much higher quality, which brings down costs. However, computers becoming much faster in terms of hardware and software is the most significant factor in all this.
A Note on GPUs
You'll often hear the term Graphics Processing Units (GPUs) in AI. Data centers deploy them to handle the large-scale processing demands of AI workloads. A GPU is a processor optimized for handling complex, computationally intensive graphical tasks. GPUs enable AI models to train on massive datasets, which makes them crucial to the ecosystem.
It's no wonder big tech companies desire them. Titans like Elon Musk can squeeze 100,000 GPUs into a single data center. It's this insatiable demand for GPUs that drives up the valuation for companies like Nvidia. Procuring more GPUs helps fuel the gold rush we've been witnessing in the markets.
GPUs rack up expenses and gobble up tons of power. However, they're a necessary part of the collaboration process that predicts the next token in the sequence.
More GPUs mean:
- You can predict and improve more tokens.
- You can process datasets faster.
To continue this series, see Introducing LLMs - Part 2
